1 属性(Attribute)
属性元素是反映单个零部件、劳动者、机器或单件运输小车特性的元素。例如,我们可以用属性来形容元素的颜色、大小、技能、成本、密度、电压或数列等。
WITNESS系统--逻辑型元素
逻辑元素是用来处理数据、定制报表、建立复杂逻辑结构的元素,通过这些元素可以提高模型的质量和实现对具有复杂结构的系统的建模。主要包括:属性(Attribute);变量(Variable);分布(Distribution);函数(Function);文件(File);零部件文件(Part
file);班次(Shift)。
1 属性(Attribute)![]()
属性元素是反映单个零部件、劳动者、机器或单件运输小车特性的元素。例如,我们可以用属性来形容元素的颜色、大小、技能、成本、密度、电压或数列等。
WITNESS系统提供了许多能用于部件、劳动者、车辆、机器或者单件运输小车的系统属性,例如:零部件、单件运输小车、车辆、机器和劳动者都带有“PEN,ICON,DESC and TYPE”属性;“CONTENTS and FLUID”属性用于盛放液体的部件;“STAGE,NSTAGE,R_SETUP and R_CYCLE”属性则是用于零部件的加工工艺路径相关属性。
另外我们也可以自己定义用于部件,劳动者,车辆,机器或单件运输小车的属性。在创建零部件属性时,可以将它分配给十一个组(0组--10组)中的任何一组,然后在零部件细节设置对话框属性设置页上,将该组属性分配给该零部件。设置的作用于零部件的属性元素可以是单维元素也可以是数组形式。
当创建劳动者、单件运输小车、机器或车辆的属性时,必须把这些属性分配给0组。劳动者、单件运输小车、机器和车辆的属性只能是单维元素,而不能是数组。
可以在仿真的过程中改变属性的值,一般使用元素细节对话框中各种类型的“Action on
****”来设置、检查或改变任何属性的值。例如,一个部件的“颜色”属性的值开始是“灰”,在部件通过了一台“着色”机器之后变成了红色,则可以在“着色”机器的“Action
on Finish”中写入:颜色="红",来实现零部件颜色属性值的改变。
2 变量(Variable)![]()
变量是用于存储特定数据的元素。在定义一个变量时,需要设置其存储数据的数据类型,主要有四种:整型、实数型、名型、字符型。
WITNESS的四种数据类型:
(1)整型(integer)
整型变量用来存储不包含小数点部分的数字。在witness中,可以是-2
147 483 648到+2 147 483 647之间的整数。
使用整数变量能够比较精确的存储数据,并且处理速度比比实数要快。但是由于整数的“循环”性,可能会使得它们过大或过小。例如:
2 147 483 647+1=-2 147 483 648
-2147483647 - 2=2 147 483 647
(2) 实型(real)
实型变量可以存储由数字(0~9)、小数点和正负号组成的数据。范围为(3.4E-38,3.4E38);
(3) 名型(name)
名型(name)变量用来存储witness仿真系统组成元素的名称。例如:
widget
miller(3)
注:函数、数值型变量、数值型属性不能够存储为名型数据。
(4) 字符型(string)
字符型变量用来存储不具有计算能力的字符型数据。字符型数据是由汉字和ASCII字符集中可打印字符(英文字符、数字字符、空格以及其他专用字符)组成,长度范围是0~4095个字符。
字符运算符
= 比较前后两个字符串是否相同;
+ 连接两个字符串
= 对字符型数据赋值
如果连接操作得出的字符型数据长度超出长度范围,witness显示出错信息。特殊用途字符串
字符型数据可以存储任何键盘上的字符。反斜线字符(\)却是一个特殊的字符。
\" 向字符串中引入一个引号(")。引号标识字符的结束。
\\ 向字符串中引入一个反斜线(\)。
\n 向字符串中引入换行符。
\r 向字符串中引入回车。
\t 向字符串中引入8个空格(TAB)字符。
\f 向字符串中引入走纸字符。如果是打印(PRINT)操作,交互窗口被清空;如果是写(write)操作,将另起一页进行写入。
WITNESS变量元素的三种类型:
(1)系统变量。这些变量是系统已经创建好了(I, M, N, TIME, VTYPE和ELEMENT)的,并且具有特殊意义的变量,它们存储仿真中常用的数据,例如,TIME表示现在的仿真时钟。
(2)全局变量。全局变量是我们自己利用“Define,
Display和Detail”过程创建的作为Witness元素的变量。
与局部变量比较起来,用全局变量的好处在于:
柔性:可以从模型的任何地方检查或更新一个全局变量的值。例如,变量“TOTAL_SHIPPED”能被模型中用于将部件送出模型的所有的元素更新。同样,任何函数,行为规则等等都可以读取“TOTAL_SHIPPED”变量中包含的值。
能生成全局变量的统计报告,但不能生成局部变量的。
能在模型中可视化动态显示全局变量和它们的值。
全局变量可以被设定为数组,我们能通过给一个全局变量1以上的下标来创建数组(行、列和数据表格),最多能创建15维的数组。
能创建一个整型或实数型的变量为动态变量,这意味着它能容纳多个值,而且该变量的长度可以动态增加或减少。在仿真运行之前,不能确定该变量需要存放的数据数量时,使用动态变量最为有效。例如,仿真过程需要使用变量shipTime来统计每个零部件离开模型的仿真时间,在仿真开始不知道在仿真运行过程中会有多少个零部件离开系统,因而就不容易确定变量shipTime数组的长度,这时设定shipTime为动态变量,在零部件离开系统时通过RecordRealValue(shipTime,Time)函数将当前仿真时间记录进动态变量shipTIme,则当第一个部件离开时shipTime中存放了1个值,其长度为1;当第二个部件离开时shipTime存放了2个值,则其长度增加为2;以此类推。
(3)局部变量。局部变量是一个我们能自己在使用它的活动或函数中创建的变量。局部变量只能是一个数,而不能是带有下标的数组。
局部变量的定义方式如下:
DIM 变量名 {AS 数据类型} {!注释}
如果省略了数据类型的定义,系统赋予变量默认的数据类型为整型integer。
用局部变量的好处在于:
安全。局部变量只有在一个行为(action)或函数执行的时候才存在,所以不可能在另一个行为(action)或函数中使用或修改它。例如,变量“TOTAL_SHIPPED”已在一个机器的“action”中被定义了,直到结束它都只能被那一系列行为更新或读取,而不能被这台机器的其它行为或模型中的其它元素更新或读取。
快速。当行为和函数使用局部变量而不是全局变量时,它们能被更快地执行。c. 方便。局部变量在使用它们的行为中被定义,不必像全局变量那样先定义它们。
3 分布(Distribution)![]()
分布元素是一个可以用来描述经验分布的逻辑性元素。当模型中相关数据服从标准的随机分布时,可以直接使用WITNESS提供的标准随机分布来描述。当模型中出现的数据不服从标准的随机分布,但是又具有特定的规律时,可以使用分布元素定义经验随机分布。例如:对老菜馆饭店的服务员数量及班次进行优化仿真时,需要根据一天当中各个时段顾客到达规律和数量来配备合适数量的服务员,通过观察发现顾客到达并不服从标准的随机分布,但是也具有一定的规律,就是在每天的11:00-13:00、17:00-19:00之间到达的人数较多,而在其他时间到达的人数相对较少,这时可以根据收集到的数据定义一个描述顾客到达饭店的规律。
Witness提供了一些标准分布。其中有一些是将一系列理论分布返回到随机样本的分布。Witness包含的理论分布曾在很长一段时间内被广泛研究并且被认为在仿真中是最有用的。还有一些是一系列整数和实数的分布。当使用一个标准分布时,必须为其输入一个伪随机数流和参数。
假如没有标准分布适用的情况,或者我们收集的现实生活中的数据是在未研究领域中的,我们可能需要在Witness中建立自己的分布并从中采样。我们能创建整型,实数型和名称型的分布,并且它们可以是离散(从分布中选择实际值)的或是连续的(从一串连续值中选择一个值)。
总的来说,假如我们有详尽的现实生活的数据,那就创建自己的分布。如果没有,那么就选择Witness提供的最适当的标准分布。
4 函数(Function)![]()
函数元素是能返回有关模型状态的信息或者使得模型显得更具有真实性的一组命令集合。
Witness提供了大量能直接使用的系统函数,例如Nparts(Buffer1)函数可以返回当前Buffer1中的零件数量;NShip(A)可以返回截止目前为止,使用Ship的方式离开系统的零部件A的数量。
同时我们也可以使用WITNESS的函数元素创建自己的函数,以实现独特的数学计算或者相关功能操作。例如,假设在计算一台机器的周期时间时要考虑多种因素,而我们在周期时间表达式中的输入又不能超过一行,在这种情况下,我们就可以自己创建一个函数,想写多少行就写多少行,然后只要把这个函数的名称输入这台机器的周期时间表达式区域就行了。
函数元素的细节设计对话框:
函数元素细节设计对话框如下图所示,右侧Type表示该函数返回值的类型,选中Integer、Real、Name或者String表示该函数将返回对应类型的数值(每个函数只能返回一种类型的数值),此时函数必须以Return语句结束;选中Void表示该函数不需要返回函数值,即该函数只是需要进行相关的数据处理即可。
函数元素还可以设置参数,通过细节设计界面右侧的Add/Remove...按钮来实现。
函数体通过点击界面下面的Action...进行设计。

5 文件(File)![]()
文件是可以使我们从仿真模型外部将数值输入模型(从一个“READ”型文件)或从模型中输出值(到
一个“WRITE”型文件)的一个元素。例如,我们能从其他软件生成的文件读入如周期时间这样的值,或者生成适当的报告。
使用文件时我们应注意以下几点:
可以用文字处理工具或文本编辑工具(或其它能生成简单ASCII 文本文件的程序)来创建“READ”文件。在这样的文件中以“!”符号开头的行被略去不读。
不要在仿真运行时对同一个文件进行读和写的操作。
假如有两个模型在仿真运行,应该保证它们不对同一个文件进行写入操作,但从同一个文件中读出是可行的。
假如要在运行中检查“WRITE”文件,应该在检查前先把它关掉,这样才能检查到一个完全更新了的文件。
6 零部件文件(Part file)![]()
“READ”型零部件文件是从外部数据文件读入零部件清单到模型中去的一个逻辑元素。
“WRITE”型零部件文件是将零部件清单写入外部文件的逻辑元素。
零部件文件可用于从一个模型中生成输出,然后将其用于另一个模型中。零部件文件对于追溯零部件离开仿真的确切时间和零部件在那时的属性值也是很有用的。使用零部件文件应注意以下两点:
不要在一个仿真运行时对同一个文件进行读和写的操作。
假如有两个模型在仿真运行,应该保证它们不对同一个文件进行写入操作,但是从同一个文件中读出是可行的。
7 班次(Shift)![]()
班次是一个能用来创建一个班次模式或一系列班次模式的逻辑元素,它可以用来控制系统中相关元素什么时段处于上班时间,什么时段处于下班时间。其它元素仿真班次工作时可以引用班次模式。我们可以将班次应用于下列元素:
缓冲 运输网络
传送装置 饼状图
流体 管道
劳动者 槽
机器 时间序列
零部件 车辆
零部件文件
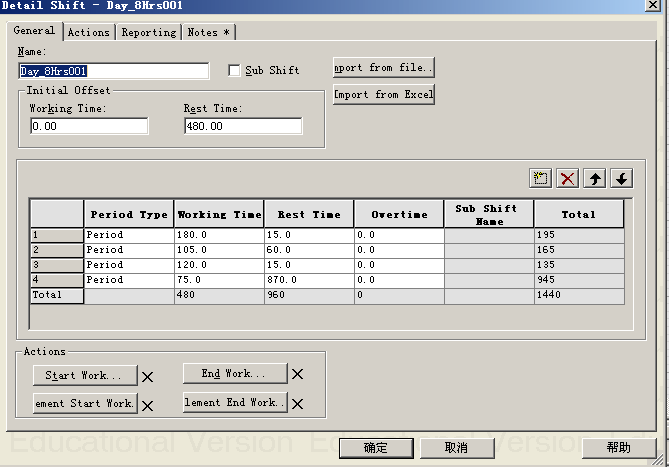
班次元素细节设计对话框:
班次元素细节设计对话框如下图所示,该图片演示的是一个每天工作8小时的班次元素细节设计界面。其假设仿真开始时间为凌晨0点,而该班次元素将在8点开始工作,则在班次初始时间补偿(Initial Offset)中设定了休息时间(Rest Time)为480;该班次元素的主体部分为4个时间周期(Period)组成,每个时间周期由一段工作时间(Working Time)+一段休息时间(Rest Time)+一段加班时间(Overtime)组成;该班次的主体部分为工作180分钟休息15分钟、然后工作105分钟休息60分钟(休息时间为午餐时间)、然后工作120分钟休息15分钟、最后工作75分钟之后下班休息870分钟(即下班回家)。